
TLDR: I wrote a Twitter bot to tweet the most interesting bioRxiv preprints. Follow it to stay up to date about the most recent preprints which received a lot of attention.
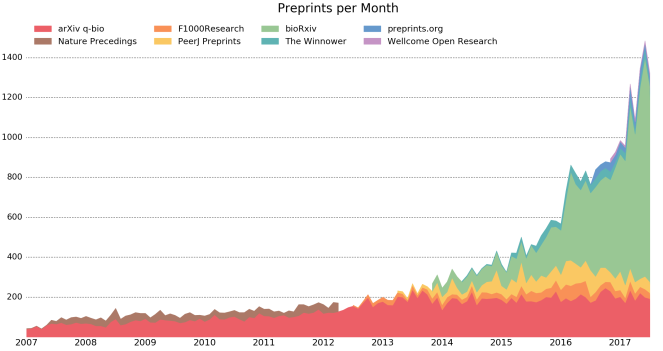
The past few months have seen an explosion of life science research papers which are first posted as a preprint. Statistics about preprints can be found on prepubmed, of which I also took the image shown below. The majority of preprints is clearly on bioRxiv, with more than 1000 submissions each month.
The idea of posting your article as a preprint is quite simple: get your results out as fast as possible, without waiting months or years for a publication in a glamorous journal. And publishing on a preprint server doesn’t prevent you from publishing in that glamorous journal afterwards, as is illustrated by the growing list of journals which accept preprints. Preprints are not peer reviewed and perhaps you should be just a bit more critical when reading. Recent developments such as Oxford Nanopore sequencing and CRISPR genome editing show why preprints are necessary: technological advances happen so fast, by the time your article is through peer-review and published your results are already obsolete and outdated. Some perspectives on preprints have been discussed in blog posts, such as What’s up with preprints?, Biology’s roiling debate over publishing research early and The selfish scientist’s guide to preprint posting, among numerous more.
This post is not meant to discuss all merits of preprints, but how to stay on top of the enormous flow of (perhaps) interesting articles. Because obviously, that amount of preprints is getting hard to follow and even harder is to find the really interesting articles between the 1000 submissions every month. It’s a needle in a haystack problem. Intro altmetric: altmetrics roughly tell you how much attention a paper/preprint received, by keeping track of all mentions and shares on twitter, blogs, news articles,…
So the hypothesis is: a preprint which gets a lot of attention (e.g. shares on Twitter) is probably a promising preprint worth reading. Based on this I wrote my Twitter bot.
Essentially, my bot will:
- Monitor the preprints submitted to bioRxiv
- Check their altmetric score
- Tweet about the preprint if it’s in the top 10% of altmetric scores in bioRxiv
To make sure the news is still hot when you get it, this checking is only performed during the first week after submission, which is a parameter I will have to evaluate.
The code to achieve this is split into two scripts:
- getPreprintsAndSave.py will run hourly, check the bioRxiv RSS feed and save articles to a file
- checkScoreAndTweet.py will run daily, check the altmetric score of the saved articles, tweet if high enough and remove old entries from the file
Both scripts are added at the bottom of this post. I use my raspberry pi 3 to run these scripts using a crontab. I have included some logging, to figure out what goes wrong if my bot doesn’t behave as expected. I’ve been thinking about the best method to store my data, but in the end, I just went with a flat text file containing doi, URL, title and date. Perhaps something else, such as an SQLite database or pickled list/dictionary might be better. Feel free to suggest how I can improve this!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Frequently check RSS, save results to database | |
| # Part of PromisingPreprint | |
| # wdecoster | |
| import feedparser | |
| from os import path | |
| import logging | |
| def checkRSS(dois_seen, dbf): | |
| ''' | |
| Check the RSS feed of biorxiv and for each paper, save doi, link and title | |
| Except if the doi was already seen, then don't duplicate | |
| ''' | |
| feed = feedparser.parse("http://connect.biorxiv.org/biorxiv_xml.php?subject=all") | |
| if 'bozo_exception' in feed.keys(): | |
| logging.error("Failed to reach the feed") | |
| else: | |
| for pub in feed["items"]: | |
| if not pub['dc_identifier'] in dois_seen: | |
| save2db(pub['dc_identifier'], pub["link"], pub["title"], pub['updated'], dbf) | |
| def save2db(doi, link, title, date, dbf): | |
| ''' | |
| Save article metrics to the database | |
| Add status 'notTweeted', since this publication is new | |
| ''' | |
| with open(dbf, 'a') as db: | |
| db.write("{}\t{}\t{}\t{}\t{}\n".format(doi, link, title, date, 'notTweeted')) | |
| def readdb(dbf): | |
| ''' | |
| Return all DOIs in the database file | |
| ''' | |
| if path.isfile(dbf): | |
| with open(dbf, 'r') as db: | |
| return [i.split('\t')[0] for i in db] | |
| else: | |
| logging.warning("Unexpected: Database not found") | |
| return [] | |
| def main(): | |
| try: | |
| db = "/home/pi/projects/PromisingPreprint/preprintdatabase.txt" | |
| logging.basicConfig( | |
| format='%(asctime)s %(message)s', | |
| filename="/home/pi/projects/PromisingPreprint/getPreprintsAndSave.log", | |
| level=logging.INFO) | |
| logging.info('Started.') | |
| dois_seen = readdb(db) | |
| checkRSS(dois_seen, db) | |
| logging.info('Finished.\n') | |
| except Exception as e: | |
| logging.error(e, exc_info=True) | |
| raise | |
| if __name__ == '__main__': | |
| main() |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ## Periodically query altmetric all entries in database younger than 1 week | |
| ## As soon as threshold (better than top 90% score journal) is passed, tweet about article | |
| # Part of PromisingPreprint | |
| # wdecoster | |
| from altmetric import Altmetric | |
| from os import path | |
| from time import sleep | |
| from datetime import datetime | |
| from secrets import * | |
| import tweepy | |
| import logging | |
| import argparse | |
| def queryAltmetric(doi): | |
| ''' | |
| Check the altmetric journal percentile score of the publication | |
| ''' | |
| a = Altmetric() | |
| sleep(2) | |
| try: | |
| resp = a.doi(doi) | |
| if resp: | |
| return resp["context"]['journal']['pct'] # Percentage attention for this journal | |
| else: | |
| return 0 | |
| except AltmetricHTTPException as e: | |
| if e.status_code == 403: | |
| logging.error("You aren't authorized for this call: {}".format(doi)) | |
| elif e.status_code == 420: | |
| logging.error("You are being rate limited, currently {}".format(doi)) | |
| sleep(60) | |
| elif e.status_code == 502: | |
| logging.error("The API version you are using is currently down for maintenance.") | |
| elif e.status_code == 404: | |
| logging.error("Invalid API function") | |
| print(e.msg) | |
| def tweet(message, api, dry): | |
| ''' | |
| Tweet the message to the api, except if dry = True, then just print | |
| ''' | |
| if args.dry: | |
| print(message) | |
| else: | |
| api.update_status(message) | |
| sleep(2) | |
| def cleandb(currentlist, alreadyTweeted, dbf): | |
| ''' | |
| Using the stored list of entries check if the articles aren't older than 1 week | |
| Save only those younger than 1 week to same file (overwrite) | |
| Also remove those which were already tweeted | |
| ''' | |
| currentTime = datetime.now() | |
| with open(dbf, 'w') as db_updated: | |
| for doi, link, title, date, status in currentlist: | |
| if (currentTime – datetime.strptime(date.strip(), "%Y-%m-%d")).days <= 7: | |
| if doi in alreadyTweeted: | |
| db_updated.write("{}\t{}\t{}\t{}\t{}\n".format(doi, link, title, date, "tweeted")) | |
| else: | |
| db_updated.write("{}\t{}\t{}\t{}\t{}\n".format(doi, link, title, date, "SeenNotTweeted")) | |
| def readdb(dbf): | |
| ''' | |
| Get all saved metrics from the database saved to file | |
| ''' | |
| if path.isfile(dbf): | |
| with open(dbf, 'r') as db: | |
| return [i.strip().split('\t') for i in db] | |
| else: | |
| return [] | |
| def getArgs(): | |
| parser = argparse.ArgumentParser(description="Checking altmetric score of preprints in database and tweet if above cutoff.") | |
| parser.add_argument("-d", "–dry", help="Print instead of tweeting", action="store_true") | |
| return parser.parse_args() | |
| def setupTweeting(): | |
| ''' | |
| Setup the tweeting api using the keys and secrets imported from secrets.py | |
| ''' | |
| auth = tweepy.OAuthHandler(consumer_key, consumer_secret) | |
| auth.set_access_token(access_token, access_secret) | |
| return tweepy.API(auth) | |
| def main(): | |
| try: | |
| args = getArgs() | |
| db="/home/pi/projects/PromisingPreprint/preprintdatabase.txt" | |
| logging.basicConfig( | |
| format='%(asctime)s %(message)s', | |
| filename="/home/pi/projects/PromisingPreprint/checkScoreAndTweet.log", | |
| level=logging.INFO) | |
| logging.info('Started.') | |
| api = setupTweeting() | |
| currentlist = readdb(db) | |
| tweeted = [] | |
| for doi, link, title, date, status in currentlist: | |
| if status == 'tweeted': | |
| tweeted.append(doi) | |
| continue | |
| pct = queryAltmetric(doi) | |
| assert 0 <= pct <= 100 | |
| if pct >= 90: | |
| tweet("{}\n{}".format(link, title), api, args.dry) | |
| tweeted.append(doi) | |
| cleandb(currentlist, tweeted, db) | |
| logging.info('Finished.\n') | |
| except Exception as e: | |
| logging.error(e, exc_info=True) | |
| raise | |
| if __name__ == '__main__': | |
| main() |

This is awesome, thanks for sharing!
Back in June, I wanted to create something similar for sociology-related research. I only got as far as prototyping it (collecting and tweeting the data manually), the process for which I describe here: http://stacykonkiel.org/sociologybot/
I may fork your code (when I finally get around to coding the darn thing) as your approach for finding articles to recommend potentially makes more sense than mine (esp. if one were to use SocArxiv as a single point for sourcing papers, rather than all of the top 10 sociology journals).
Anyway–great work! Thanks for making your code open source!
LikeLike
I’m glad you find it useful. Please let me know if you need help adapting the code for your application.
LikeLike
This looks great. Have you considered adding other preprint servers? You can get in touch if you need info about accessing data from preprints.org.
LikeLike
Hi Martyn,
Thank you for reaching out. Did I understand correctly that preprints.org is a separate/non-overlapping server/repository for preprints, without restriction of research area? If so, I’d be happy to set up a twitter bot for these too, in case an RSS feed is available and the preprints are included in Altmetric.
Cheers,
Wouter
LikeLike
Hi Wouter,
Yes, we have a similar setup to bioRxiv and cover all disciplines. There is an RSS feed at https://www.preprints.org/rss and our preprints are on altmetric (see e.g. https://www.altmetric.com/details/35365527). Thanks.
LikeLike
Okay, should be quite easy to clone the current bot and create a new one for preprints.org
I’ll probably do it on Monday.
LikeLike